Early last year we were looking for a time series database (aka TSDB) to replace the Postgres SQL database used in our initial product prototype, as the timeline queries for serving some UI components are becoming unbearably slow when the data entries reaches 10 million in the underline table. Clearly Postgres is not the best option for this job.
What to Look for in a TSDB?
Time-based Partitioning
Time series data is usually queried by a time range. Partitioning the ingested data by time range into smaller segments will greatly improve the query performance, because only the set of segments fall into the time range need to be queried.
Retention Policy and Downsampling
In time series data based applications, the following technique is commonly used to reduce the data storage size, optimize the operational cost and query responsiveness:
- Real-time time series data has the highest precision and highest data volume. It’s usually configured for shorter retention, e.g. for only 4 hours.
- The highest precision data is downsampled to coarser-grained data, e.g. 10 minute summary. Then the coarser-grained data is configured for longer retention, e.g. for 2 days.
- The coarser-grained data is downsampled to even more coarse-grained data, e.g. hourly summary. The hourly summary is configured for longer retention, e.g. for 1 year.
- Based on the time range chosen by the end user, data with proper granularity fitting in that time range will be retrieved to serve the client query.
The availability and flexibility for setting up the retention policy , and down sampling of the TSDB will make the implementation of the above technique much simpler.
Open Source Options
Base one our research, we have shortlisted a few popular open-source TSDB as potential candidates to replace Postgres’s role in serving timeline and analytic queries:
- Prometheus
- InfluxDB
- Apache Druid
Prometheus was quickly ruled out as it is not designed to be scaled horizontally at the time of evaluation. Druid is having a very scalable architecture, but it is more involved to setup, administrate and set up the data ingestion. Meanwhile InfluxDB is very easy to be set up on the dev desktop, therefore we first started the evaluation with InfluxDB.
InfluxDB
We started with the evaluation with the InfluxDB 1.7 release which was the latest version one year ago. The single instance version is very easy to install on the dev box. The open source version is available in Google Cloud marketplace and can be easily installed in a GKE cluster. Here is the pros and cons we found when using InfluxDB:
Pros:
- With REST API and client library for direct data ingestion
- Low latency: most of the queries returns in a few milli-seconds
- InfluxQL is SQL like: very easy to learn and get up-to-speed
- Easy to set up retention policy
- Easy to set up continuous query (aka CQ) for data downsampling
Cons:
- Clustering solution needs a commercial license
- Performance degrades when the data cardinality reaches 1 million and data ingestion errors out if exceeding configured cardinality limit
Since our SaaS application is multi-tenant, we would like our backend TSDB to be able to persist time series data coming from different customers. We quickly found out that InfluxDB will hit the cardinality limit even in our staging/testing environment and result into data ingestion failures. Therefore we have to move to evaluate the next candidate Apache Druid.
Apache Druid
Apache Druid is a horizontally scalable, real-time analytics database designed for fast slice-and-dice analytics (“OLAP” queries) on large data sets. It’s a distributed system with quite a few components. The high-level architecture looks like below:
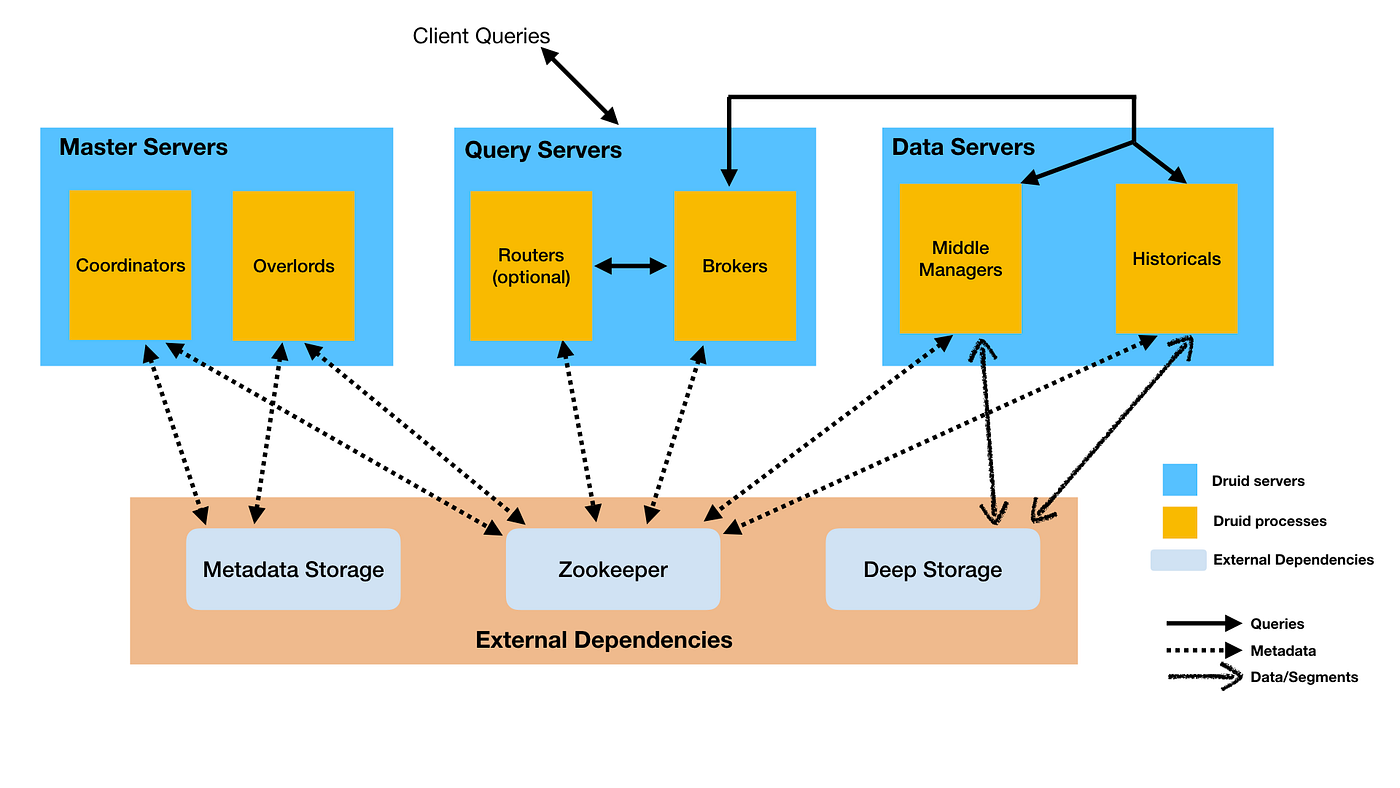
Setting up a production ready Druid cluster in Kubernetes is quite involved. I will write another article to cover the details. Below is what a small Druid cluster looks like after being deployed into GKE.

Here is a list of pros and cons we found in evaluating and using Druid.
Pros:
- Handles high cardinality data very well
- Horizontally scalable architecture
- Data retention can be set at data source level
- Time-based data partitioning
- Ingestion time rollup
- SQL based query option available
- Sub-second query latencies with common time ranges
Cons:
- Quite involved to set up a fully functional cluster
- Need expertise to optimize the CPU/storage/Memory configurations of various components
- Need to set up a Kafka cluster just for data ingestion: no direct REST API based ingestion.
- Quite heavy for local development, need a desktop with higher CPU/Memory spec.
- No SQL like command to upgrade ingestion spec, need to call
druid/indexer/v1/supervisorREST API instead. Also schema changes are applied only to future ingested data, not retroactively.
Although it’s quite some work to set up Druid cluster compared with InfluxDB and operate it efficiently, but it’s horizontal scalability, capability of handling high cardinality data at ease and flexibility of slice-and-dice query make it a good choice as one important piece in our data platform.
Final Architecture
We started building our data ingestion platform around Apache Druid. The high-level architecture diagram of the platform is shown below. We have omitted the following components in the diagram to avoid cluttering:
- Configuration data store:
Postgres - Discovered entity store:
Google Cloud Datastore - Raw data payload store:
Google Cloud Storage - Hot data caching, and pubsub messaging between components:
Redis Cluster

Conclusion
Even though it’s a little involved to set up a production-ready Druid cluster in Kubernetes initially. Once the cluster is set up properly, it’s working like a charm. Druid is a very scalable platform. We just need to add more nodes to the cluster when it’s running out of resources, so far we have seen nothing major with it.
We have being running the Apache Druid cluster in our staging/production environment stably for the last 9 months already. It’s serving as the backbone of our data infrastructure. Our data analytics is built upon Druid’s capability of serving various slice-and-dice queries with very reasonable latency (usually a couple of hundreds of milli-seconds). We are very happy with the investment with Druid.









